华为最近揭秘了CloudMatrix 384超节点方案的更多细节。这一方案基于384颗自研昇腾芯片,采用全互连拓扑架构,实现了高达300 PFLOPs的BF16算力,接近英伟达GB200 NVL72系统的两倍。同时,其内存容量和带宽分别超出英伟达方案的3.6倍和2.1倍,为大规模AI训练和推理提供了强大支持。
华为推出CloudMatrix 384,其实是在用“系统能力”对冲“单芯片差距”。虽然昇腾单颗芯片还追不上英伟达Blackwell,但华为这次玩的是大局观——用384颗芯片的全互联架构,把整体算力和内存带宽拉到一个新高度,直接针对AI训练中的通信瓶颈下手。
它不是在芯片性能上硬刚英伟达,而是在算力组织方式上另辟蹊径,用大规模协同和全互联架构打破传统GPU集群的通信瓶颈,这也是华为对“下一代AI算力形态”的理解。



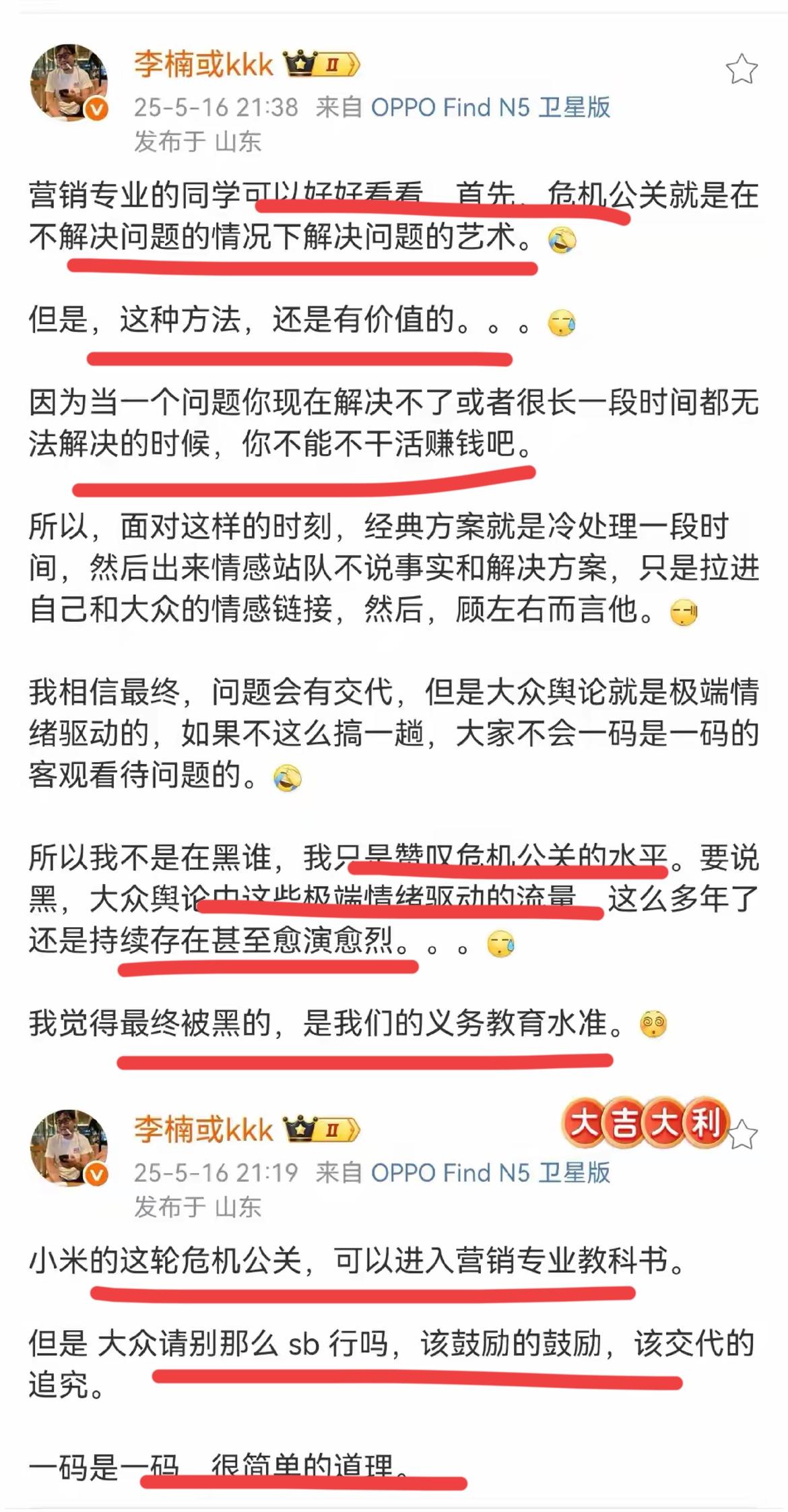
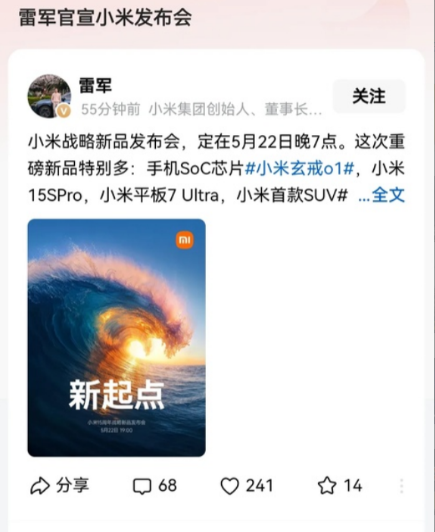

![网传玄戒o1的跑分单核2700+多核8100+但是核心显示为十核?[吃瓜]小米玄](http://image.uczzd.cn/16613101695609579597.jpg?id=0)