AI推理也讲节奏感AI推理先快后慢更聪明
大模型也讲节奏感,先慢后快反而更聪明?
这篇AK大佬转发的清华姚班校友论文,提出了一个有趣概念:大模型推理并非线性展开,而是一个节奏变化的动态过程。
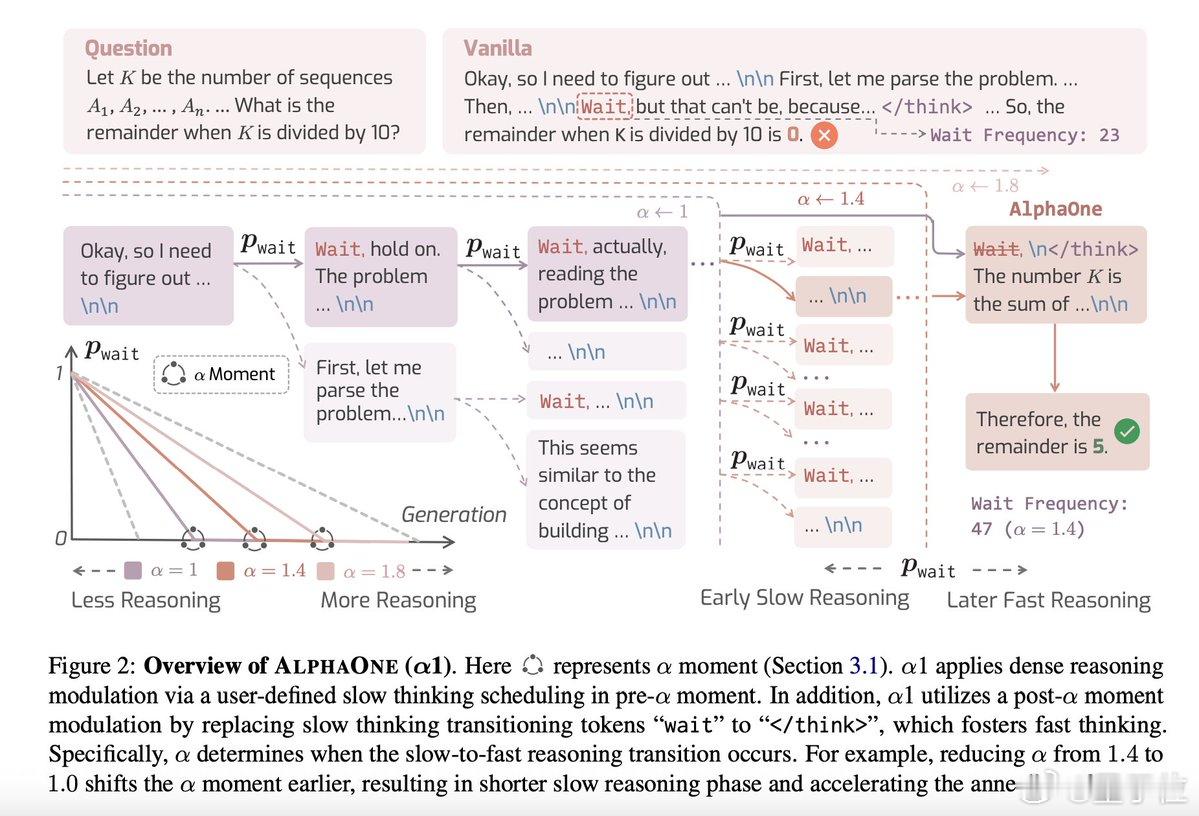
基于此,研究团队提出了一种新方法——AlphaOne (α1),能调控大模型推理时的“慢思考”和“快思考”。
这项方法的核心观点是:
AlphaOne方法引入一个参数α,通过它控制模型何时“慢下来”,何时“提速”。整个流程可以拆解为两段:
1. 慢速阶段(前期):模型在生成答案时会插入“wait” token,相当于给自己一些时间进行更深层次的思考。这些token不是固定插入,而是根据一个动态策略(如线性退火)来逐步减少频率。
2. 快速阶段(后期):到了设定的“α时刻”,系统自动切换到快节奏,停止等待并用特定token(比如“”)终结深度推理,输出答案。这相当于把“磨刀时间”集中在最开始,后半段迅速收尾。
这一方法带来多方面优势:
- 效率更高:与传统“全程快速”或“随机快慢”策略相比,α1在保持准确率的同时,显著减少了推理所需的token数量,平均节省14%;
- 准确率提升:在多个高强度推理任务中(如数学竞赛AIME24、AMC23,代码生成LiveCode,以及科学竞赛Olympiad),α1表现优于现有方法,如s1(线性加速策略)和CoD(递减节奏策略),准确率提升6%-13%;
- 泛化能力强:无论是1.5B还是32B规模的模型,α1都适用,不依赖具体模型架构;
- FREP指标领先:研究团队提出一个衡量“推理效率与表现平衡”的新指标FREP(Reasoning Efficiency-Performance),α1在各项测试中得分最高。
此外,研究还指出几个容易被忽视的细节:
- Post-α modulation不可或缺:如果不强制结束“wait”,模型会陷入“过度深思”状态,导致性能下降,实验中甚至损失高达20%的表现;
- 节奏调控不能太极端:插入等待token太少或太多都会适得其反,α不是越大越好,一个合适的α值能最大化准确率和token效率。
总的来看,α1用极简单的方式,将复杂推理流程划分为“慢-快”两个阶段,在不需重新训练、不依赖外部工具的前提下,就能显著增强模型智能。
顺带一提,论文一作是Runpei Dong博士,他目前就读于伊利诺伊大学香槟分校,在此之前,他于2024年获得了计算机科学硕士学位,期间在清华大学交叉信息研究院(IIIS)和西安交通大学联合培养,由姚期智院士指导。
完整论文链接: