用强化学习教LLM学汇编斯坦福提升LLM汇编能力
斯坦福新研究:用强化学习提升LLM汇编能力,性能超过了gcc -O3。
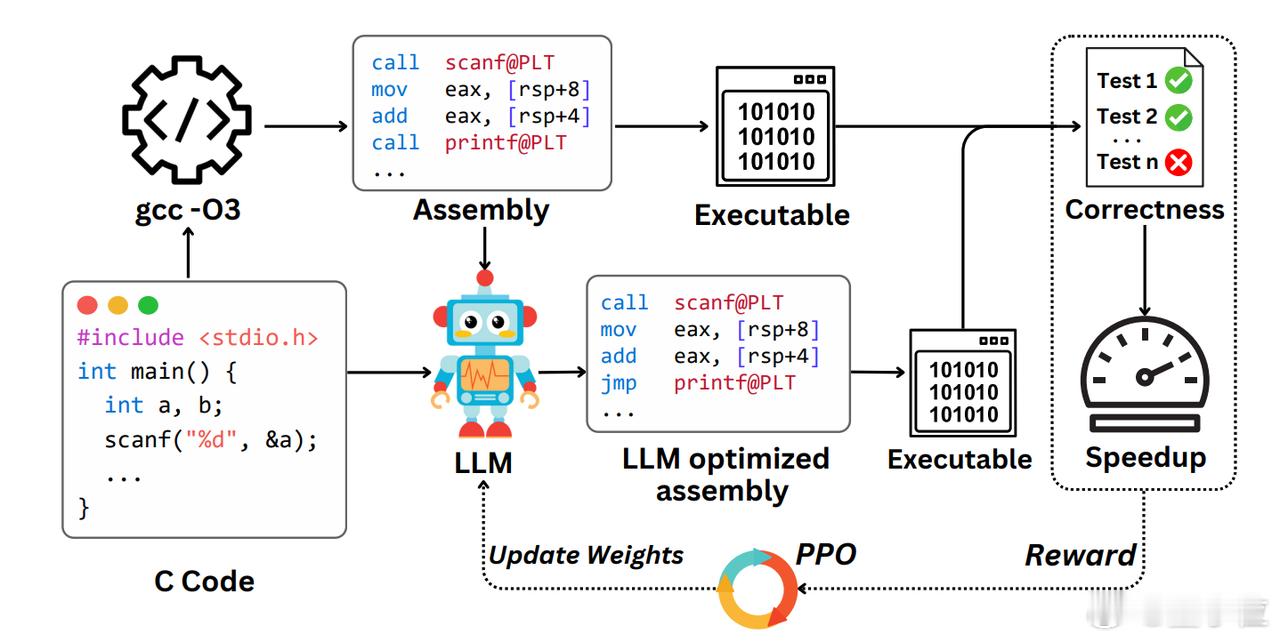
他们用了一种叫PPO(Proximal Policy Optimization)的强化学习方法,让模型像游戏一样“闯关”,每次输出一个新版本的汇编代码,如果跑得更快、测试不报错,就能拿到“奖励”,从而不断提升奖励分数。
整个过程可以理解为三步走:
1、准备数据:整理了一个超大的训练集,包含8072个真实世界的C程序、它们的gcc -O3汇编版本,以及一套专门的测试用例。
2、模型选型:用Qwen2.5-Coder-7B-Instruct模型作为基模型。
3、强化训练:让模型在生成汇编代码时不断试错,又对又快才得分,逐步学会哪些修改才是真的“性能提升”。
训练结果非常硬核:
- 测试通过率从原始的61%提升到96%
- 平均加速比达到 1.47×,明显超过 gcc -O3
- 模型能主动做出类似“用popcnt指令替代循环”这样的语义级优化,而不是简单套模板
值得注意的是,这套机制强调的是“优化”而不是“生成”:
- 研究发现,完全让模型从头写汇编,LLM表现一般
- 但只要给它一个gcc的输出作参考,它就能在此基础上进一步提速,类似人类“看着编译器输出再调一调”的做法
总结来看,这项研究的亮点在于:
- 用强化学习提升LLM汇编能力,不再只追求语言理解,而是走向实用层面的系统性能优化
- 它不是替代编译器,而是在编译器之后再进一步提升,是一种新的优化“后处理”思路
- 长远看,大模型未来可能成为编译器工具链中的一环,接手人类最难调的代码瓶颈
未来搞极限性能优化时,也许不需要硬核工程师手改汇编了,直接把任务甩给一个强化学习过的LLM,它就能把gcc编出来的程序优化得飞起。
感兴趣的小伙伴可以查看论文: