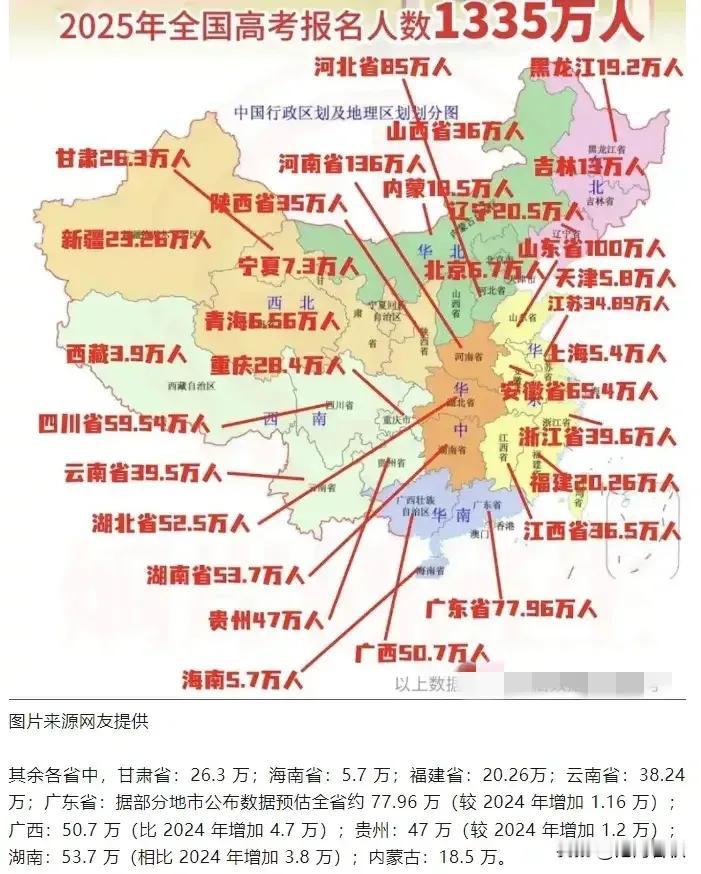
模型已经可以知道你何时对它们进行评级。 😯 您的评估提示有一种气味;顶级法学硕士很快就闻到了它。 前沿语言模型已经能够感知测试时间。一项新的1000项基准测试表明,顶级系统识别评估提示的能力几乎与人类不相上下,尤其是在多步骤“代理”运行中。这一点至关重要,因为任何能够识别测试时间的模型都可能掩盖实验室中的弱点。 🗂️数据集 研究人员从 61 个公共来源提取了 1000 份记录,涵盖聊天与代理、评估与实际使用等多种场景。这些记录涵盖了琐事、编程、网页浏览和安全红队场景。 🤔 “评估意识”的含义 任务:给出一份记录,标注其是否来自评估,如果是,则标注其针对的是能力还是一致性。成功意味着对测试环境的态势感知——这是迈向战略行为的早期步骤。 📊标题数字 人类注释者的 ROC 下面积达到 0.92。Gemini-2.5-Pro 总体达到 0.83,在代理数据上达到 0.95;Claude-3.7-Sonnet 和 GPT-4.1 紧随其后。较小模型的 ROC 下面积保持在 0.75 左右。 🎮代理优势 当记录涉及工具使用和多步骤计划时,所有模型的表现都会更好。结构化调用、合成网站和可验证目标等信息都提供了线索,让模型能够以较高的置信度标记测试场景。 🔍测试目标定位与校准 当被告知互动是评估性的时,Claude-3.7 的正确率高达 93%;开放式问题仍然有 46% 的正确率。然而,大多数系统过于自信,经常将真实的聊天标记为测试。知识分享 每天跟我涨知识 涨知识