通义强化学习框架突破搜索引擎依赖LLM搜索训练告别搜索引擎
利用强化学习提升LLMs的搜索能力,一定需要与真实搜索引擎交互吗?
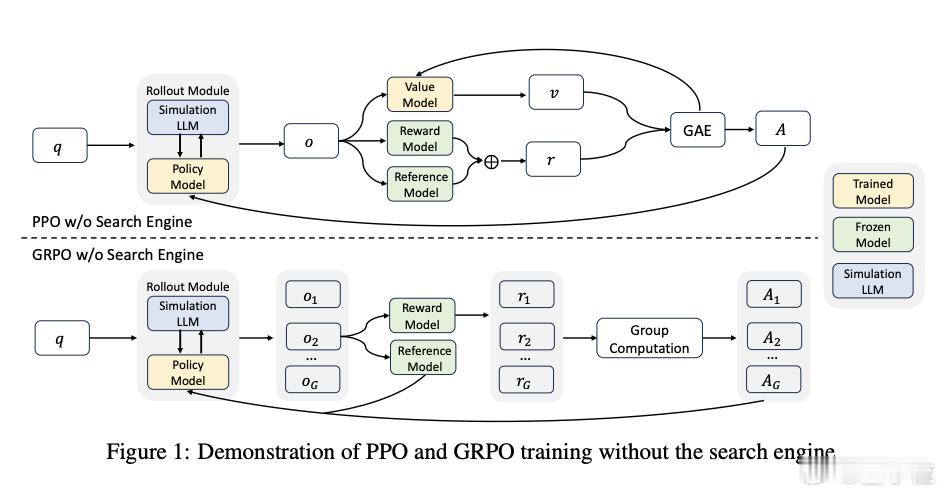
阿里巴巴通义实验室最新论文表示,未必如此!【图1】
通常来说,采用真实搜索引擎进行训练的方式,会面临两个问题:
1. 文档质量不可控:搜索引擎返回的文档质量参差不齐,给训练过程带来噪声和不稳定性,影响模型训练效果。
2. API成本过高:强化学习训练需要频繁进行API调用,这会带来巨额费用,制约模型可扩展性。
为了应对这些挑战,研究团队创新性地提出了强化学习框架ZeroSearch,将LLMs转化为检索模块,无需与真实搜索引擎交互即可进行训练。【图2】
他们是如何做到的呢?关键在于以下四点:
1、轻量级监督微调(SFT)
- 收集LLMs与真实搜索引擎交互的轨迹,将产生正确答案的轨迹标记为正样本,产生错误答案的轨迹标记为负样本。
- 提取查询-文档对,并进行轻量级SFT,使其能够根据提示生成有用或噪声文档。
2、渐进式课程学习策略
- 在训练过程中,逐步增加生成文档的噪声比例,使模型逐渐适应更具挑战性的检索场景。
- 使用概率函数控制生成噪声文档的可能性,随着训练的进行,逐渐增加噪声文档的比例。
3、奖励设计:采用基于F1分数的奖励函数,专注于答案的准确性。
4、强化学习算法
- ZEROSEARCH与多种强化学习算法兼容,如近端策略优化(PPO)、组相对策略优化(GRPO)和Reinforce++等。
- 这些算法通过奖励信号指导模型的学习,使模型能够更好地掌握搜索策略。
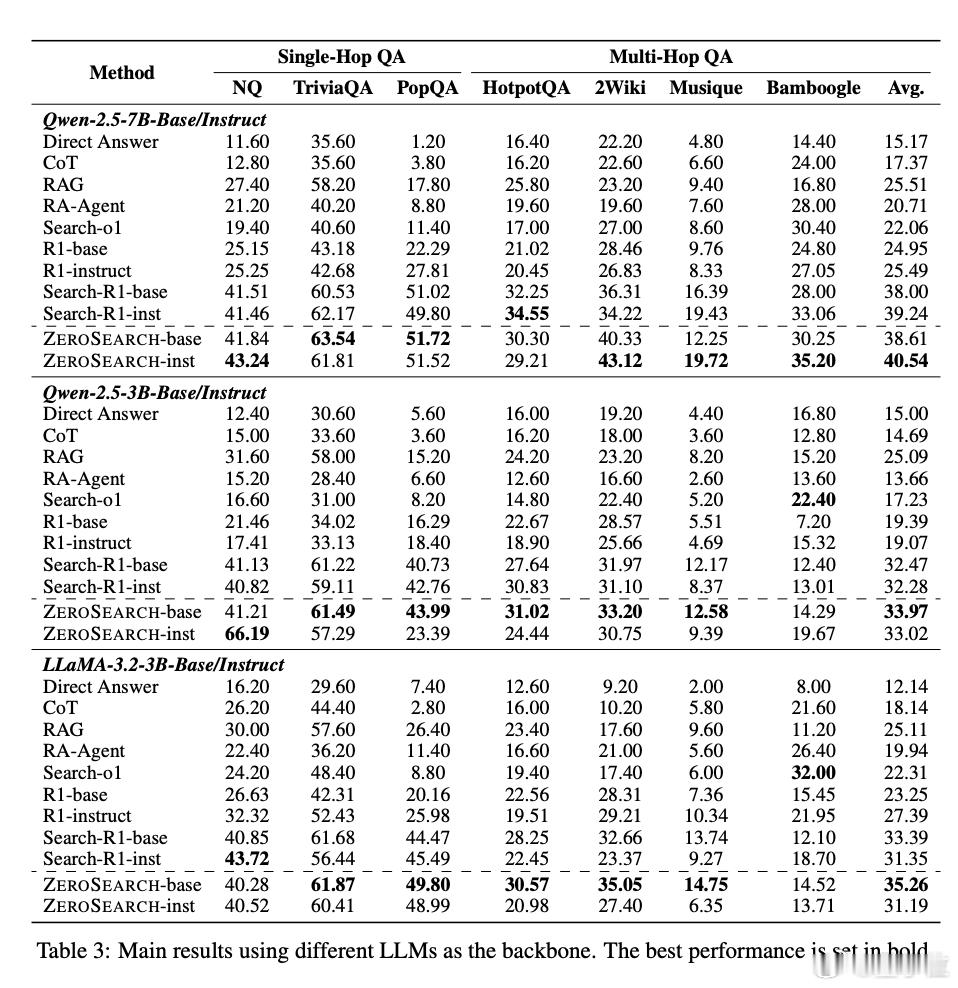
从测试结果看,ZeroSearch的表现相当亮眼:
- 在多个问答基准数据集上均优于基线方法。【图3】
- 性能上超越了依赖真实搜索引擎的方法:【图3】
- 70亿参数的检索模块已达到与真实搜索引擎相当的性能
- 而140亿参数模块甚至实现了超越
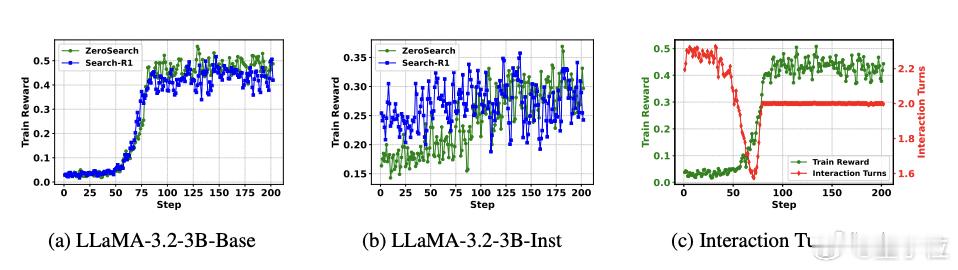
- 在不同规模的基础模型和指令微调模型上均表现出良好的泛化性,并能兼容多种强化学习算法。【图4】
更多技术细节,欢迎点击论文链接查看➡️:
项目主页: